
·

Jul 17, 2026
Generative UI lets AI build the screen each user needs, in real time. What it is, how it works, the trade-offs, and two working demos we built.

12 read time
Generative UI is a full-stack architecture that lets AI create, modify, and render user interfaces in real time, based on what each user needs at that exact moment. Instead of static, predefined screens, the interface assembles itself on the fly: a bar chart, a table, a comparison card when you're comparing things.
We've been building proofs of concept with it for the past few weeks. Most of what's written about generative UI is either too abstract or too exciting, so this is our attempt at neither: what it is, how it works, where it helps, where it doesn't, and what we learned from two demos we built.
The short version
- Generative UI means the AI designs the screen that answers your question, not just the answer.
- In production, most systems don't let the AI write code. It configures pre-built components. Safer, and good enough.
- It shines in open-ended workflows like reporting and data exploration, where you can't pre-design every screen someone might need.
- It complements standard UI. It doesn't replace it. Anyone telling you otherwise is selling something.
What is generative UI?
Generative UI is a full-stack architecture: the backend talks to the LLM, decides what the answer should look like, and picks the components, while the frontend renders them and handles how the user interacts with what’s on screen.
Compare that with how interfaces have always worked. A designer decides what goes on each screen, a developer builds it, and every user sees the same thing. Forever, or until the next redesign.
Generative UI flips that. The interface becomes dynamic and personal instead of static and universal. The AI doesn't just answer your question, it designs the screen that answers your question.
Dashboards and reporting are the most common use cases, but they're far from the only one. The same pattern works for dynamic forms, onboarding flows, and customer support, as it takes input just as easily as it presents output. It can even adjust font size, contrast, or layout for users with low vision, color blindness, or cognitive load.
The three types of generative UI
There are three levels of generative UI, from most constrained to most open (Google Cloud, 2026):
- Static. Everything is pre-built. The AI picks which screen to show you from a fixed library. Low risk, low flexibility.
- Declarative. The AI assembles a JSON tree that specifies which UI components to use, in what order, with what properties. It doesn't write code. It configures pre-designed widgets. This balances the AI's flexibility with the system's stability.
- Open. The AI generates completely new code from scratch and the frontend renders it. Maximum flexibility, maximum risk.
Most production systems today use the declarative approach, and that's what this post assumes from here on. The AI isn't writing HTML or CSS freestyle. It selects components, fills in pre-designed widgets, and composes them into the right screen.
How does generative UI work?
Generative UI works by turning a user request into structured data that describes an interface, then rendering that data as real components. The flow looks like this:
- The user asks for something, explicitly or inferred from context.
- An LLM analyzes the request. It invokes tools, pulls data, and makes the design decisions: what to show and how.
- The system generates structured data describing both the components and the information they'll display.
- That schema travels to the frontend through the AG-UI protocol, a standard for communication between agents and frontends. It defines events that keep the agent's state in the backend synchronized with the frontend framework.
- The frontend transforms the schema into actual widgets and renders them.
To the user, the result feels like magic. Behind the scenes, it's structured data flowing through a well-defined pipeline. We prefer the second description. It's the one you can build on.
Pros and cons of generative UI
Generative UI trades real personalization and faster development for added latency, inference costs, and less predictable layouts. That's the honest version. Here are the details.
What you gain
What you pay for it
None of these are dealbreakers. There are known techniques to mitigate each one.
Generative UI examples: two working demos
We built two demos. One with fictional data, one on top of a tool we use every day.
Aurora Goods: a conversational e-commerce dashboard
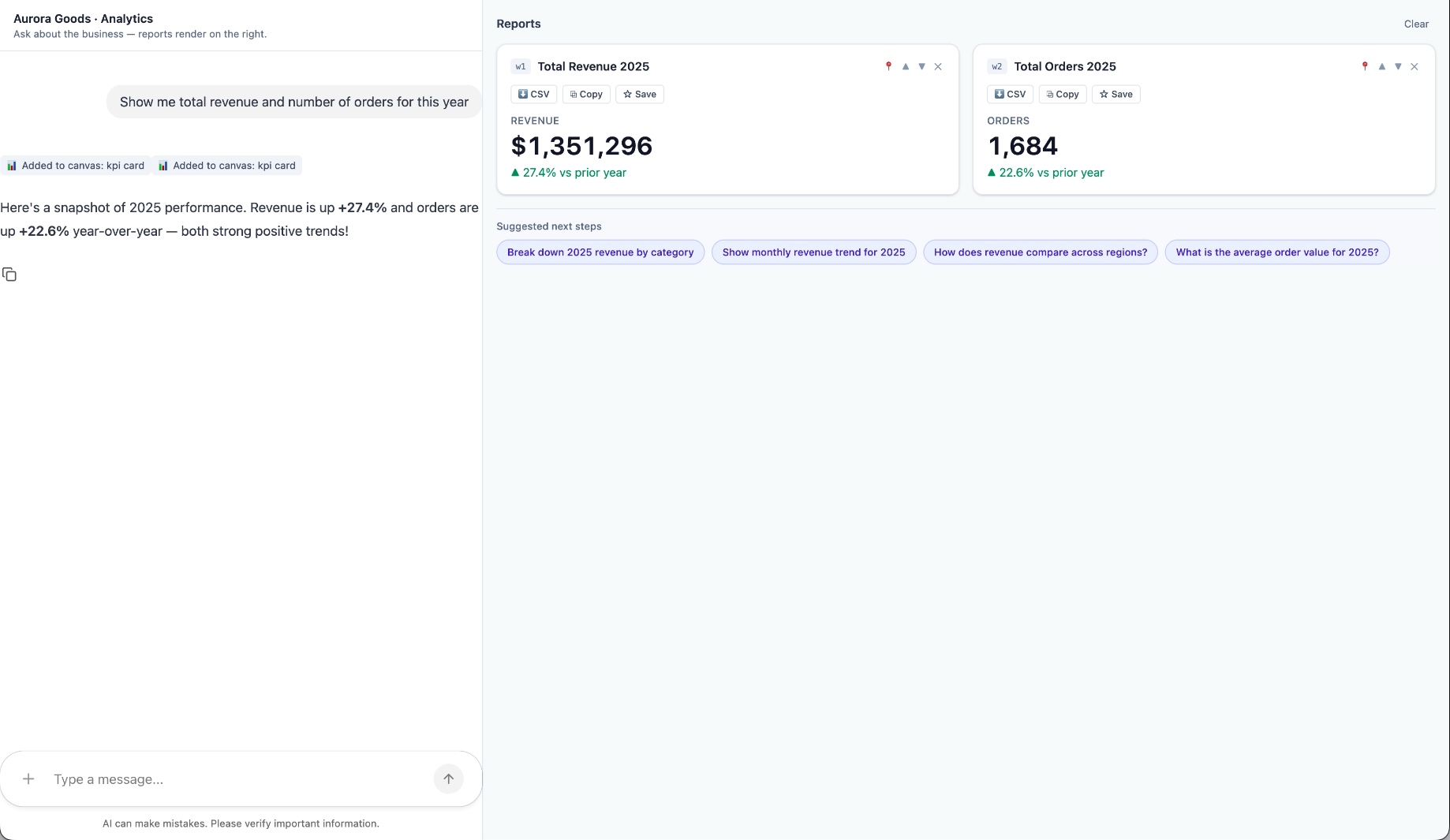
Aurora Goods is a fictional consumer e-commerce platform we created for the demo. The interface is simple: chat on the left, canvas on the right. You ask about the business, the LLM figures out what you need, pulls the data, and renders it visually.
Ask about 2025 sales and it shows the numbers on cards, with a short note on anything relevant. Ask it to break that down by region and it extends the same view instead of starting over, because it understands the second question builds on the first. This part took us a while to get right, and it's what makes the whole thing feel like a conversation rather than a search box.
The canvas isn't output-only either. You can click into any element and drill down: revenue by category, then inside electronics, then which products sold most.
You configure the widgets once. The system combines them and adds relevant commentary on the spot.
An internal reporting screen for our time-tracking tool
The second demo is closer to home: a generative reporting layer on top of the time-tracking tool we use every day at Kaizen. The questions in this demo are questions someone here has actually asked.
Instead of building dozens of hyper-specific reports, a small amount of code now handles virtually unlimited queries. How many hours were logged in May? Which anomalies showed up in April? How do billable and non-billable hours compare across two months? Who worked on a given project last month, and for how long? Each answer arrives as the right visualization: cards, lists, bar charts, plus a short summary that's easy to scan.
Two details won us over. The LLM suggests next steps, so exploring the data becomes a conversation. And when it's not sure, it asks instead of assuming. Ask for the hours of someone named Alex and, since we have more than one Alex on the team, it asks which one before answering.
Generative UI complements standard UI. That's the point.
Generative UI is a complement, not a replacement. Standard interfaces still win for stable, repetitive workflows where consistency matters. Nobody wants their checkout button to be creative. Generative UI wins where the workflow is complex and the questions are unpredictable.
It also changes what design systems are for. Beyond designing components and screens, teams will need to define semantic rules: how the AI should react to uncertainty, which interfaces match which intentions, and the guardrails that keep generated screens functional and safe.
That's a new kind of design work. And it's already starting.
Want to see generative UI applied to your own data?
We build working proofs of concept in two weeks. Your data, your workflows, a real thing you can click.