We’ve all been there: we want to learn about a new framework or technology so we go to its official webpage and carry out the online tutorial. Unfortunately, these tutorials generally aim to cover a basic first approach to the tool, but not enough when we want to use them for something more complex such as creating a product for a production environment. The aim of this blog then is to provide some tips on how to approach learning a new framework or technology.
I remember when I used to have more free time at work and decided to learn how to use React. I carried out the online tutorials from the official website, which I found quite interesting but I was not even close to being able to use it in a complex project. For example: one of the tutorials only covers React components and hooks, but not its characteristics which are highly important in a webpage, such as:
Authorization and authentication handling using OAuth.
Using external libraries, as in some technologies this may be complex. Such is the case of Expo. Docker deployment or any other solution.
You may be thinking: that’s what the advanced guide on the website is for, as it even tackles even more complex topics. While I agree with that, those guides fail to give answers to the above mentioned, which I believe are quite basic and should be present in any production solution.
That is why, I believe the best way to learn a new technology is by trying to simulate a project including all the characteristics a production solution should have. I know it’s not easy to come up with a good idea for a project and then develop it so thoroughly. Instead, I suggest not to bother so much about the functionality of the project in itself.
If we want to implement authentication and authorization using OAuth, it isn’t really important whether we try it in a social network system or in an account management software, what’s really important is that certain routes access, websites or resources are restricted according to the characteristics we consider important. So don’t waste time trying to think of an appealing idea, just roll up your sleeves and get down to work.
In the same line of thought, during my last stay on the bench (which is what we say in Kaizen when someone has not been assigned to any client yet) I decided to learn how to use NestJS to implement a solution using microservices. While I was acquainted with that topic as I had seen it in University, I never had the chance to put it into practice. The first thing I did was to resort to something very good we have here at Kaizen: our workmates!
In Kaizen developers work in teams which are assigned to different clients. Different teams often use different technologies and architectures. Developers at Kaizen are always willing to help their peers, even if they are not part of the same team, so I decided to ask one of my colleagues working with microservices for help.
This colleague told me about the technology they used to implement microservices in his project and some tips on what to bear in mind when using it. Based on that I came up with a list of characteristics which are necessary for a solution of this kind:
Service mesh, to facilitate communication among microservices, state handling, etc.
Database connection to maintain changes in the system.
You can have several instances of deployment.
Since there is a service mesh, setting up a debugger is not always so simple.
Track what’s going on in the system and how good its performance is.
Use Swagger to be able to try the services exposed by the API.
Use OAuth for authentication and authorization.
As you can see, there are many things to bear in mind. This is why it is highly advisable to count with a working plan to help you work out the different steps and to set short term goals to feel motivated. This is how I planned it:
API Rest with NestJS.
Create microservices using @NestJS/microservices.
Docker deployment.
Service mesh using Dapr and connecting the microservices.
Docker-compose deployment.
Use a state manager from Dapr to establish a database connection.
Docker image adjust to support deployment in Kubernetes.
As you can see, I made some changes based on my own experience and interests. For example, I made the database connection using Dapr as connecting databases from Node.js isn’t very different from doing it using NestJS. Moreover, I split the deployment in two as first I wanted to learn docker, then docker-compose and finally Kubernetes.
I may not have the same experience I have using other frameworks and implementing a solution based on what I learnt may not be so fast and efficient. However, I consider that I have learnt how to use NestJS, Dapr, Docker, Kubernetes satisfactorily. I could also create a Github repository where I have everything ready if I have the opportunity to put it all into practice in a real situation with a client. This repository can also be used to pass on knowledge to future colleagues.
Conclusion
In conclusion, learning a new framework is not only about following some basic tutorials, but more like diving into simulating projects which involve more complex characteristics and challenges. By simulating a project with characteristics necessary for a production solution, we can gain practical knowledge and face common obstacles present in the real world.
In addition, seeking peers and experts' support aids our learning and offers us a broader perspective. Designing a working plan and setting up short-term achievements can help us feel motivated and to obtain non-stop progress. Finally, this approach allows us to develop hard skills and to create a knowledge repository that we can share with others in the future.
We’ve all been there: we want to learn about a new framework or technology so we go to its official webpage and carry out the online tutorial. Unfortunately, these tutorials generally aim to cover a basic first approach to the tool, but not enough when we want to use them for something more complex such as creating a product for a production environment. The aim of this blog then is to provide some tips on how to approach learning a new framework or technology.
I remember when I used to have more free time at work and decided to learn how to use React. I carried out the online tutorials from the official website, which I found quite interesting but I was not even close to being able to use it in a complex project. For example: one of the tutorials only covers React components and hooks, but not its characteristics which are highly important in a webpage, such as:
Authorization and authentication handling using OAuth.
Using external libraries, as in some technologies this may be complex. Such is the case of Expo. Docker deployment or any other solution.
You may be thinking: that’s what the advanced guide on the website is for, as it even tackles even more complex topics. While I agree with that, those guides fail to give answers to the above mentioned, which I believe are quite basic and should be present in any production solution.
That is why, I believe the best way to learn a new technology is by trying to simulate a project including all the characteristics a production solution should have. I know it’s not easy to come up with a good idea for a project and then develop it so thoroughly. Instead, I suggest not to bother so much about the functionality of the project in itself.
If we want to implement authentication and authorization using OAuth, it isn’t really important whether we try it in a social network system or in an account management software, what’s really important is that certain routes access, websites or resources are restricted according to the characteristics we consider important. So don’t waste time trying to think of an appealing idea, just roll up your sleeves and get down to work.
In the same line of thought, during my last stay on the bench (which is what we say in Kaizen when someone has not been assigned to any client yet) I decided to learn how to use NestJS to implement a solution using microservices. While I was acquainted with that topic as I had seen it in University, I never had the chance to put it into practice. The first thing I did was to resort to something very good we have here at Kaizen: our workmates!
In Kaizen developers work in teams which are assigned to different clients. Different teams often use different technologies and architectures. Developers at Kaizen are always willing to help their peers, even if they are not part of the same team, so I decided to ask one of my colleagues working with microservices for help.
This colleague told me about the technology they used to implement microservices in his project and some tips on what to bear in mind when using it. Based on that I came up with a list of characteristics which are necessary for a solution of this kind:
Service mesh, to facilitate communication among microservices, state handling, etc.
Database connection to maintain changes in the system.
You can have several instances of deployment.
Since there is a service mesh, setting up a debugger is not always so simple.
Track what’s going on in the system and how good its performance is.
Use Swagger to be able to try the services exposed by the API.
Use OAuth for authentication and authorization.
As you can see, there are many things to bear in mind. This is why it is highly advisable to count with a working plan to help you work out the different steps and to set short term goals to feel motivated. This is how I planned it:
API Rest with NestJS.
Create microservices using @NestJS/microservices.
Docker deployment.
Service mesh using Dapr and connecting the microservices.
Docker-compose deployment.
Use a state manager from Dapr to establish a database connection.
Docker image adjust to support deployment in Kubernetes.
As you can see, I made some changes based on my own experience and interests. For example, I made the database connection using Dapr as connecting databases from Node.js isn’t very different from doing it using NestJS. Moreover, I split the deployment in two as first I wanted to learn docker, then docker-compose and finally Kubernetes.
I may not have the same experience I have using other frameworks and implementing a solution based on what I learnt may not be so fast and efficient. However, I consider that I have learnt how to use NestJS, Dapr, Docker, Kubernetes satisfactorily. I could also create a Github repository where I have everything ready if I have the opportunity to put it all into practice in a real situation with a client. This repository can also be used to pass on knowledge to future colleagues.
Conclusion
In conclusion, learning a new framework is not only about following some basic tutorials, but more like diving into simulating projects which involve more complex characteristics and challenges. By simulating a project with characteristics necessary for a production solution, we can gain practical knowledge and face common obstacles present in the real world.
In addition, seeking peers and experts' support aids our learning and offers us a broader perspective. Designing a working plan and setting up short-term achievements can help us feel motivated and to obtain non-stop progress. Finally, this approach allows us to develop hard skills and to create a knowledge repository that we can share with others in the future.
A while ago we noticed something pretty common: everyone wanted to share more knowledge internally, but nobody wanted another heavy corporate ritual.
Internal talks usually start with good intentions and slowly disappear. They take time, preparation, and energy. And at some point people start feeling like they need to be experts before presenting anything.
So we tried the opposite.
15 minute talks.
Small topics.
Low pressure.
And one important rule: every session had to leave something useful behind. A tool, a workflow, an idea, a shortcut, a new way to approach a problem. Something people could actually use after the talk ended.
We didn’t want theory that went nowhere.
Somehow, that ended up working much better than we expected.
The idea was to reduce friction
Screenshot of the shared topic pool
Tiny Knowledge Bytes is intentionally simple:
anyone can suggest topics
anyone can end up presenting
you don’t need to master the topic
talks can come from experiments, client problems, tools or random discoveries
sessions should leave something practical behind
if nobody volunteers, the system picks someone for us
The goal was making knowledge sharing feel lightweight instead of exhausting.
Some of the best talks start with:
“I tried this yesterday and it was weird.”
The topic pool started growing on its own
Over time, topics started coming from everywhere.
Sometimes someone took a course and used a Tiny Knowledge Byte as a way to give something back to the team. Other times, a client problem triggered research into new tools, workflows or AI approaches.
A lot of sessions start from curiosity or necessity more than planning.
And honestly, the mix is part of what makes it interesting.
Sometimes a UX session drifts into Computer Vision. Sometimes someone technical shares a visual workflow that half the design team ends up adopting later.
There’s not much curation. It behaves more like a constant exploration system.
Then another problem appeared: choosing who presents
And this is where things became unnecessarily dramatic.
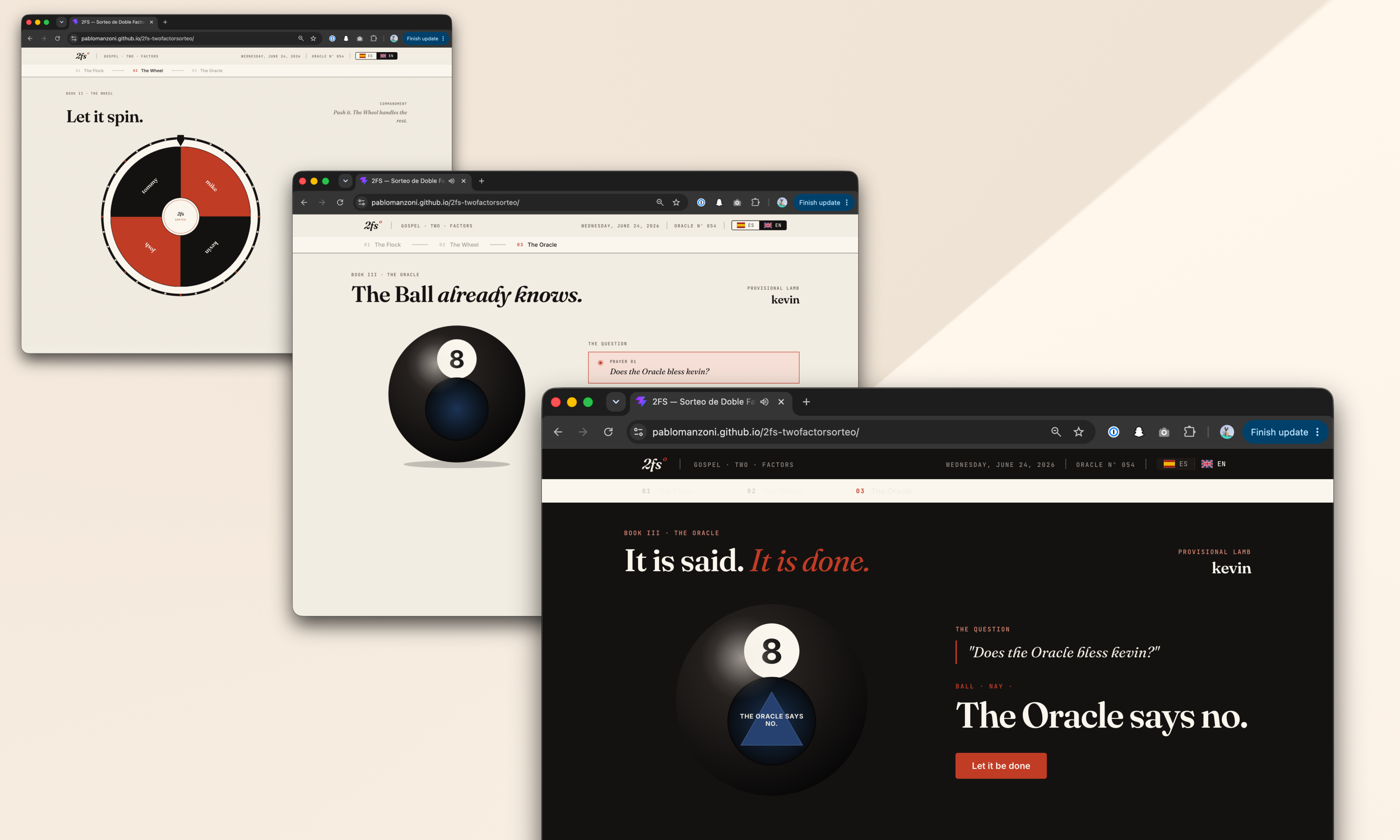
Nobody wanted to be “the person who chooses”. So we started adding absurd layers of randomness until we somehow ended up building a full internal app called 2FS.
Two Factor Sorteo.
Yes, it’s real.
The wheel proposes. The oracle decides.
The logic is simple.
First, a wheel picks someone.
Then a Magic 8 Ball decides whether destiny approves the selection.
If the oracle rejects the person, the process starts again.
That’s it.
The app accidentally became part of the learning loop too
Apps developed for the Tiny Knowledge Bytes.
2FS originally started as an excuse to experiment with:
Claude Code
Claude Design
design systems
editorial interfaces
motion and microinteractions
Eventually those same explorations turned into future Tiny Knowledge Bytes.
The tool we used to select speakers started generating new topics itself.
The system started feeding itself
One of the most interesting side effects is that people started building things outside their usual role because of previous Tiny Knowledge Bytes.
2FS itself is a good example. A designer saw sessions about Claude tooling and AI workflows and thought:
“Maybe I can actually build this.”
What started as a ridiculous speaker selection tool became a real product experiment involving Claude Code, interface systems and interaction design.
Then it came back into the Tiny Knowledge Bytes circuit as a new talk.
That loop became surprisingly valuable:
someone learns something,
tries it,
builds something with it,
and eventually inspires someone else to do the same.
What ended up mattering most
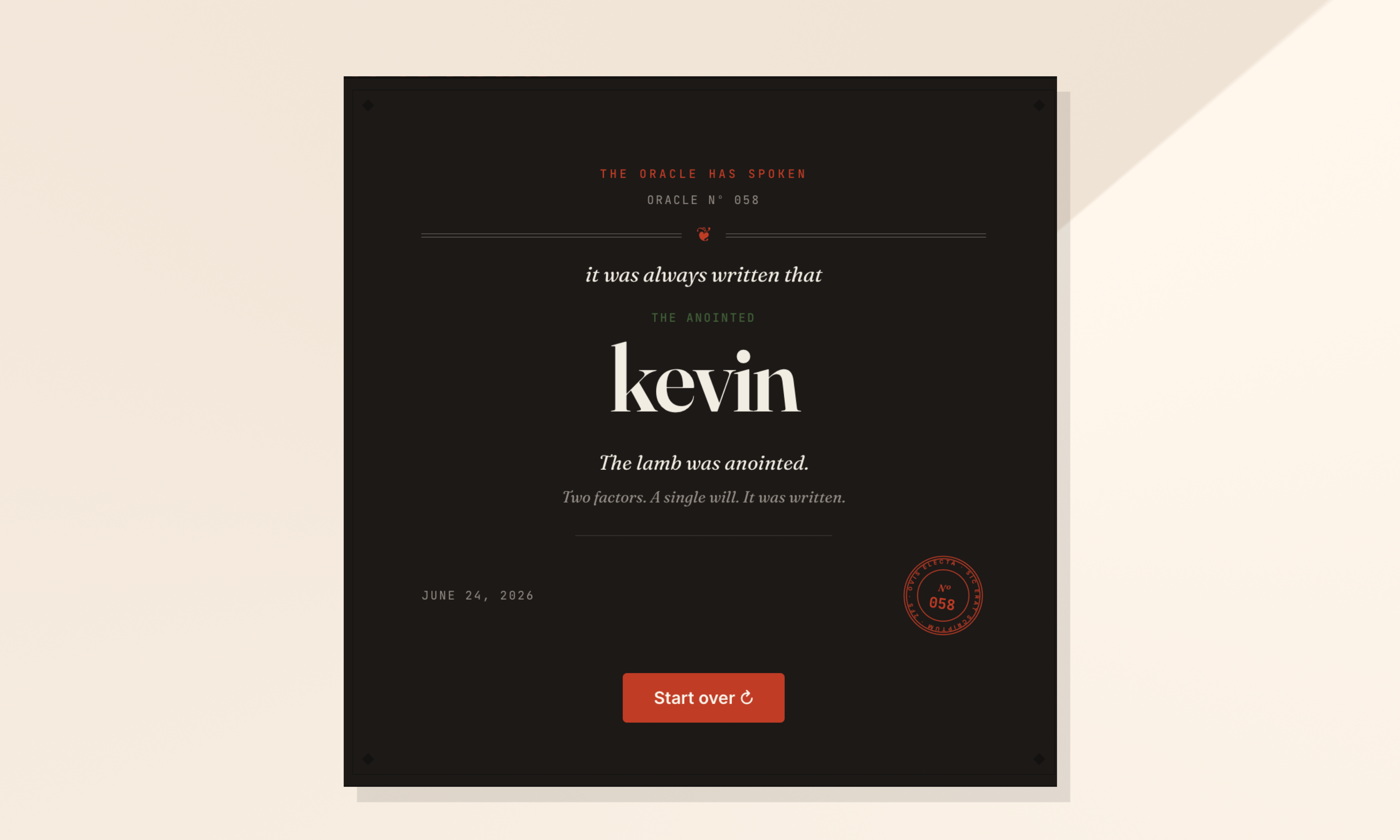
Final Oracle Certificate.
Over time we realized knowledge sharing works much better when:
it doesn’t require huge preparation
it’s allowed to be imperfect
it mixes different disciplines
it leaves something practical behind
and somehow involves a mystical wheel connected to a Magic 8 Ball
At that point, it stops feeling like another internal obligation and starts feeling like something people genuinely want to keep alive.
Just this month, I built a full design system in about 20 hours.
What used to take weeks, sometimes months, is now dramatically faster. So… what actually changed? And more importantly: what didn’t?
Design systems take time. On complex platforms, they can take hundreds of hours.
We were working with a large and complex product where inconsistencies had started to pile up. Different modules had evolved in isolation, teams were making independent decisions, and there were no shared guidelines. The answer was clear: we needed a design system.
AI tools were just starting to emerge back then. They were mostly useful for simple tasks as they tended to hallucinate when things got complex. Developers had started using them earlier than designers, MCP didn't exist yet, and Figma plugins were the best automation we had.
But the context has changed. Fast.
The Manual Era
We did what most teams did. We stopped, and we built it. Manually.
Picture two designers, a mountain of inconsistencies, and no map. We had to cross-reference information manually, digging through the code, detecting what could be merged, agreeing on naming conventions, deciding how to name components. Hours and hours of discussion until we finally landed on a solution.
In the end, we got there. A cleaner system, faster workflows, and for the first time, both teams speaking the same visual language. Hard-won, but it worked.
But now every month a new AI model seems to be released. Design is finally catching up with what developers faced about two years ago. New tools arose, and with that, the scope of our work as designers completely changed.
The Human Factor
For an internal project, I used our Kaizen site as a reference, combined with documentation from industry leaders as a guideline.
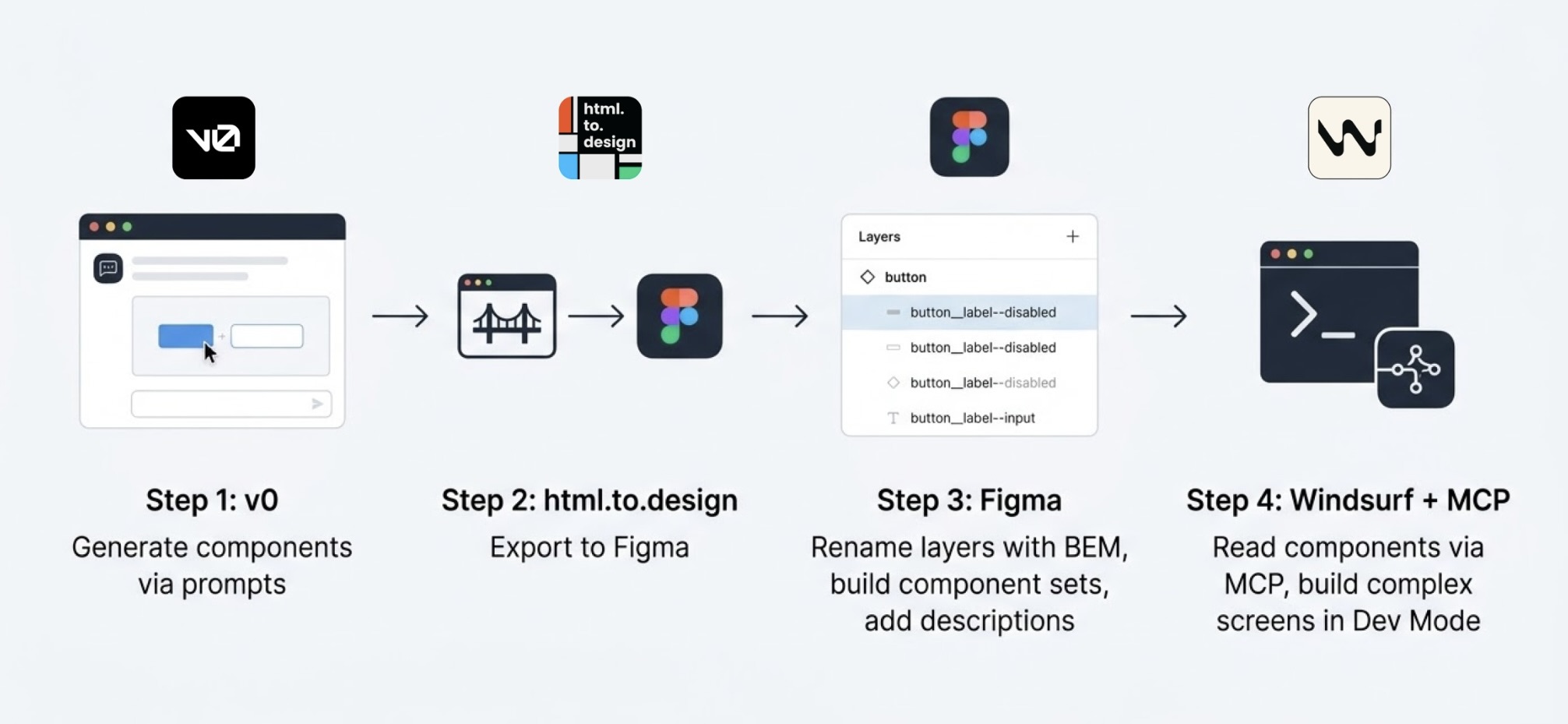
I started in v0, which is essentially a chat interface where you can generate UI components through prompts. I fed it the colors, typographies, and a reference image, and from there it was a back-and-forth: the AI generated, I reacted, adjusted, and pushed until the output matched what I had in my head. And just like that, I started prompting my way through a Design System.
Once a component was ready, I used the html.to.design plugin to bring it into Figma (yes, plugins are still alive!). Think of it as a bridge: the plugin exports designs directly from the browser into a Figma file.
Inside Figma, the intervention was more hands-on. First, I checked that everything was visually consistent with what was defined in v0: colors, typography, styles. Then I used Figma's built-in AI to rename all the component layers using BEM convention (something that would have taken a significant amount of time to do so manually).
BEM, which stands for Block Element Modifier, is a widely adopted naming convention in CSS. It structures layer names hierarchically and predictably, for example: button__label--disabled.
Using it keeps the code clean, readable, and consistent, especially when you're working alongside a developer who needs to understand what came out the other side.
Beyond naming, I also made sure the layer structure would generate the right properties when building component sets in Figma, so that all the variants would be correctly exposed and usable. My team also pointed out that adding descriptions to components and variants was key as context for any agent using them through an MCP.
The last step was connecting everything to Windsurf via MCP. With a frame selected in Dev Mode, Windsurf could read the Figma file and use the components to build more complex screens.
We worked closely with a developer throughout this phase. Not just for the technical knowledge, but because having someone who reads code fluently meant catching things we wouldn't have spotted otherwise. The design role here was direction and supervision: making sure the AI used the components correctly and didn't invent solutions where context was missing.
Every step of the process had a human decision behind it.
An Unexpected Discovery
At one point, before we had any of the naming conventions figured out, I selected a frame and asked Windsurf to build a form using the components inside it, styled to match a specific card. The developer next to me was skeptical until he saw the result, and then he was just as surprised as I was.
What we realized is that the MCP wasn't reading layer names to understand context. It was reading everything inside the frame, even the loose text sitting alongside the components. Good naming is still worth doing. But the MCP doesn't need it to understand what it's looking at.
Learning to Talk to an AI
The more specific and contained your prompt, the better the outcome. We started with the most atomic component: the button, and worked outward from there. Each approved component became context for the next one, so the system gradually picked up the visual language we were building.
At some point I got ambitious and asked for five cards in a single prompt: blog card, service card, testimonial card, stats card, feature card… structures, states and all. The AI delivered.
Visually, everything looked fine. Then the developer looked at the code and pointed out that all five cards were independent components instead of variants of one. For a design system, that breaks everything.
One correction prompt fixed it. But it was a good reminder: the AI does exactly what you ask, not what you mean. And fixing it after the fact can cost more than getting it right from the start.
Some Things Learned Along the Way
Precision is key. Natural language is fine when you're asking for a cooking recipe, but when referring to a component, if you say things like "create" instead of "add", you'll probably end up with a whole new set of components instead of additional variants of an existing one.
The "Frame" is the context: MCPs can read everything inside the frame you select. This is a game-changer. It means the "naming conventions" debate might be shifting. If the AI understands the context visually and structurally, will we still spend hours discussing nomenclature in 2027?
No matter what happens, you can always roll back in less than 5 minutes and start over.
Work closely with a developer: they can help you understand MCPs and clear up any code-related doubts. Once you start to grasp their logic, you'll learn very quickly how to prompt in ways that AI actually understands.
There's nothing to lose by asking the AI to follow a specific naming convention for the code. It keeps everything clean and readable, and it takes no extra effort.
The AI covers roughly 80% of the work (generation, variations, exploration...), but the remaining 20% is where quality lives, and that part is not delegable. The AI executes. The judgment is still yours. And if you skip the review, you're not saving time: you'll spend it later.
Context matters more than tooling. What you don't define, the AI will invent. Small components may be resolved well, but large interfaces require more definition from the start. A well-defined system scales. An undefined one generates inconsistencies faster than you can fix them.
Figma is no longer the mandatory starting point. It's useful as a visual reference, a QA space, or a consolidation layer. But the AI doesn't need it. We still do.
There's no single right workflow yet. What you do depends on the project. We're in a transition moment where the tools change faster than the standards. The best thing you can do right now is experiment.
What AI Still Can’t Replace
Through all of this, a few things became very clear. These are the parts that didn’t change:
Knowing when something looks off. The AI generates, but it doesn't notice when the result doesn't feel right. That eye is yours.
Direction and supervision. The AI used the components we gave it, but without someone supervising it, it invents solutions where there is no context to work from.
The definition of done is still a human call, whether it's a conversation with a PO, a stakeholder, or just the designer's criteria. There's no prompt for that.
The context: knowing why certain decisions matter, what a component should communicate, what the user will actually feel. Business knowledge, stakeholder dynamics, unwritten rules, empathy for the end user. These take years to build and live in the people doing the work, not in the tools they use.
My Two Cents
The tools changed, and that gave me the chills, but throughout this experience I found that the designer's role is more alive than ever.
What once took a team weeks can now be prototyped in hours. That’s not a threat; it’s an invitation to get curious.
I'm still figuring a lot of this out, and I suspect most of us are. There's no right workflow yet, and honestly, that's fine. We are in a transition where tools change faster than standards. The best thing you can do is experiment. Don't wait for a "definitive" workflow, it might be obsolete by next month.
Go ahead, try prompting your way through a component. You might be surprised how fast the system starts to take shape.